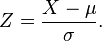
Twee jaar geleden publiceerde ik een artikel over kwantitatieve evaluatietechnieken voor bibliotheekcollecties : "
collecties evalueren". Daarin beschreef ik zeer kort de verschillende methodieken en kan men (nog steeds) een
Doe-het-zelf-formulier downloaden.
De laatste tijd voel ik steeds meer voor één van de aangekaarte methodieken : de
Z-score. Deze methodiek werd niet speciaal ontworpen voor bibliotheekcollecties, maar is een vrij courante statistische methode om verschillende populaties met elkaar te vergelijken. In ons geval worden deze populaties collectieonderdelen.
Iedereen in de bibliotheekwereld is (zou) vertrouwd (moeten zijn) met de klassieke basistechnieken als bezitscoëfficiënt, leenfrequentie en gebruikscoëfficiënt (turnover rate). Deze technieken zijn misschien goed voor basale benchmarktoepassingen en normeringen, maar zijn zeer beperkt in hun toepassing binnen de bibliotheek, omwille van het ontbreken van statistische relevantie. Anders gesteld : wat moeten we met die cijfers ? Wat betekent een turnoverrate van 2,3 voor onze bibliotheek ?
Aan de andere kant van het spectrum hebben we dan de integrale benadering van systemen als het Integraal Collectiebeheer (ICB) (ontwikkeld door
Bureau Leemans). Hiermee krijgt men kant-en-klare-collectieadviezen.
Toch kan Z-socere een tussenweg bieden. Het is (uiteraard) veel beperkter dan het ICB-model, maar het biedt in combinatie met goed uitgewerkte collectieprofielen een efficiënt alternatief.
De Z-score is alvast hanteerbaarder dan andere modellen zoals Gütersloh en Doucet-Larbre.
De Z-score is afgeleid van de Use-factor (die dan weer gelijkenissen vertoont met de turn-over-rate). Bij de Use-factor bepaalt men voor elk collectieonderdeel het relatieve aandeel in de gehele uitleen en het relatieve aandeel in de totale collectie. Het eerste getal wordt door het tweede gedeeld.
% uitleningen van een rubriek / % bezit van een rubriek
Indien het bekomen getal groter is dan 1 is het aanbod in die rubriek te klein, indien het kleiner is dan 1 is het aanbod te groot.
Het grote probleem is echter dat de Use-factor (zoals alle berekeningen op basis van percentages en gemiddelden) zeer gevoelig voor uitschieters. Dit kan bijvoorbeeld een schrijver of een onderwerp zijn die een hype veroorzaakt. Bij gemiddelden kunnen die uitschieters geneutraliseerd door gebruik te maken van de
standaard-afwijking (zoek maar eens
STDEV op bij de Excel-functies).
Dit is ook wat de Z-score gebruikt om een evenwichtig beeld te verkrijgen van de collectie. Deze methodiek gebruikt de Use-factor voor elk collectieonderdeel, maar trekt daar de gemiddelde use-factor van de totale collectie af en deelt dit door de standaardafwijking.
Een evenwichtige collectie ligt dan tussen -1 en 1.
Dries Calleeuw maakte een mooie case over een
muziekafdeling en hier vindt u een
leeg formulier voor eigen gebruik.
Zoals eerder gesteld moet deze werkwijze gecombineerd worden met duidelijke collectieprofielen en een duidelijke
beleidsvisie (zie mijn vorige post).




